The research on Likelihood Matching for Diffusion Models by Lei Qian, Wu Su, et al. has been accepted by ICML.
Lei Qian et al.'s research on Likelihood Matching for Diffusion Models accepted by ICML
Recently, the research paper "Likelihood Matching for Diffusion Models" by Professor Song Xi Chen’s team has been accepted by the International Conference on Machine Learning (ICML), a top-tier international conference in the field of artificial intelligence and machine learning. Approaching from the perspective of Maximum Likelihood Estimation (MLE), the paper proposes a novel training framework for diffusion models termed "Likelihood Matching." This work provides a new methodological pathway for advancing the theoretical analysis and enhancing the generative performance of diffusion models.
Diffusion Models have become a foundational methodology in modern generative artificial intelligence, with strong performance in image synthesis, protein design, and data augmentation. Existing mainstream diffusion models are typically trained through Score Matching, which learns the score functions of perturbed data distributions at different noise levels. From a statistical perspective, however, Score Matching optimizes an upper bound of the negative log-likelihood rather than directly maximizing the data likelihood itself. Developing a more direct, efficient, and theoretically grounded training principle based on Maximum Likelihood Estimation is therefore an important problem in generative learning.
This work proposes a new training framework for diffusion models, named Likelihood Matching (LM). The method first establishes an equivalence between the likelihood of the target data distribution and the likelihood along the sample path of the reverse diffusion process. Based on this equivalence, the paper adopts a Quasi-Maximum Likelihood Estimation approach to construct a tractable approximation of the otherwise intractable reverse transition densities. Specifically, each reverse transition density is approximated by a Gaussian distribution with matched conditional mean and conditional covariance. Together with the arbitrariness of the time points along the diffusion path, this leads to an optimizable quasi-likelihood objective.

Figure 1. Illustration of Score Matching (a) versus Likelihood Matching (b).
Unlike conventional Score Matching, which primarily uses first-order moment information, Likelihood Matching incorporates both the score function and Hessian information. In this way, it unifies score matching and covariance matching, while also naturally realizing likelihood weighting. The paper further introduces a stochastic sampler based on the conditional mean and covariance structure, enabling the generation process to leverage both the estimated score and Hessian functions. To reduce the computational burden in high-dimensional image data, the Hessian is parameterized using a diagonal-plus-low-rank structure, and efficient computation is achieved through the Sherman-Morrison-Woodbury formula.
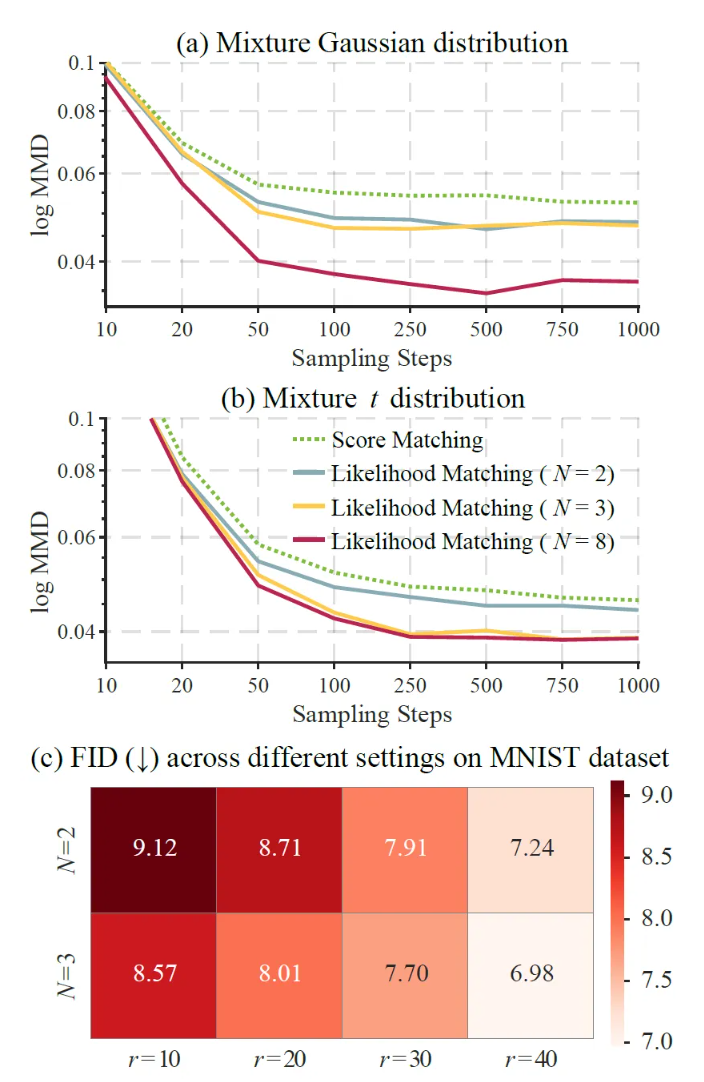
Figure 2. Maximum Mean Discrepancy (MMD; lower is better) between generated and true samples under two one-dimensional mixture distributions: (a) Gaussian mixture and (b) t-mixture with 3 degrees of freedom, with respect to the number of sampling steps (N). (c) Fréchet Inception Distance (FID; lower is better) on the MNIST dataset for different combinations of ((N, r)) under the Likelihood Matching framework.
Experimental results demonstrate that Likelihood Matching consistently outperforms the conventional Score Matching baseline across multiple tasks. In mixture distribution experiments, LM achieves lower MMD values, and its performance improves as the number of transition steps increases. In parameter estimation experiments, LM obtains lower mean absolute error and standard error than Score Matching. On image generation tasks, LM achieves better generation quality and likelihood performance on MNIST, CIFAR-10, and CelebA 64×64. MNIST sampling results further show that, with fewer reverse iterations, LM can generate structurally clearer digit images more rapidly.

Figure 3. Sampling comparison on the MNIST dataset.
The first author of the article is Lei Qian, a 2023 master’s student at the Center of Data Science of the Academy for Advanced Interdisciplinary Studies at Peking University. Professor Song Xi Chen is the corresponding author and also Lei’s master’s supervisor. The other student authors include Wu Su, a 2023 Ph.D. student at the Center for Data Science, Peking University, also supervised by Professor Chen, and Yanqi Huang, a 2023 Ph.D. student at Guanghua School of Management, Peking University. This research was supported by the National Natural Science Foundation of China Grant Nos. 12292980 and 12292983.
Article link:
https://www.songxichen.com/Uploads/Files/Publication/Likelihood_Matching_for_Diffusion_Models.pdf